3 min to read
Inductive Bias에 대한 고찰 - 그래서 그게 뭔데?
Inductive bias(유도 편항)에 대해, bias-variance trade-off 관점에서
CNN, ViT 관련된 논문이나 글들을 보다보면 _inductive bias_라는 용어가 종종 보이곤 한다. 뭔가 CNN에 관련된 모델이 가지고 있는 사전 지식? 같은 느낌의 단어로… 느낌적으로는 알겠는데 정확히 이게 뭔가? 라고 물어봤을 때 대답할 수 있을 지 의문이 들어 글을 쓰게 되었다.
Inductive bias에 대해 본격적으로 탐구하기 전에, _bias_는 무엇인지 살펴보자.
Bias & Variance
머신러닝을 처음 공부하는 사람이라면 누구나 한번쯤 들어봤을 개념, bias & variance trade-off 되시겠다.
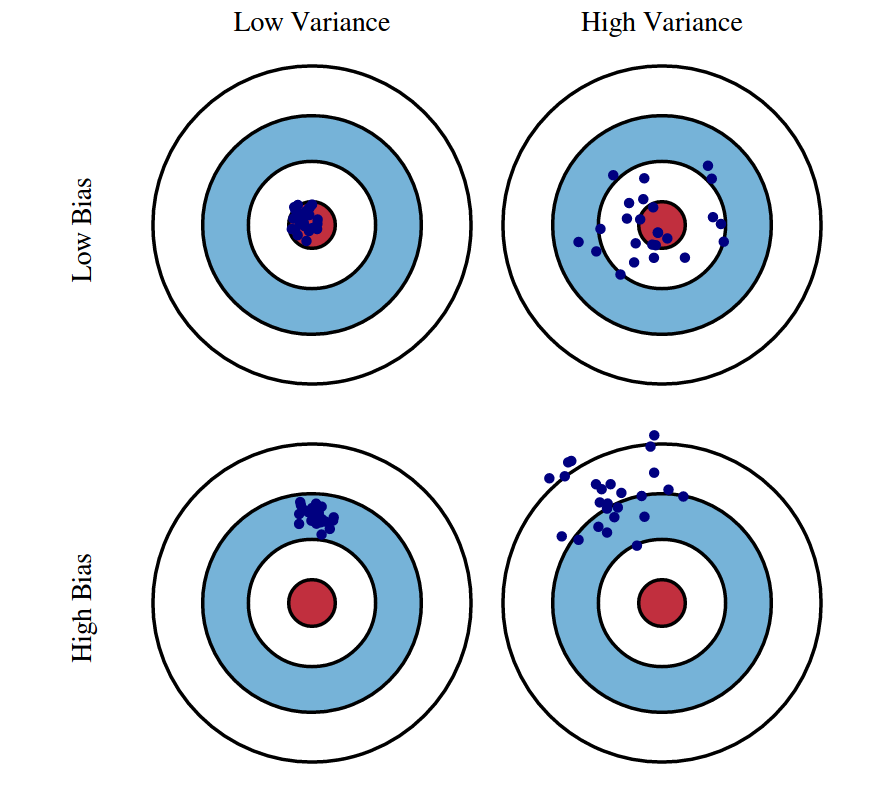
나는 bias & variance에 대한 개념을 설명할 때 위 그림을 사용하는 것을 좋아한다. 실제로 내가 처음 bias & variance 개념을 배울 때에도 위 그림을 참고했다. 직관적으로, bias가 크면 뭔가 모델의 예측치가 한 지점에 몰려있는 느낌이고 variance가 크면 여러 지점에 퍼져있는 느낌이다. bias와 variance가 동시에 큰 경우 예측값이 퍼져 있으면서 정답값과 멀리 떨어져 있기 때문에, bias와 variance를 줄이는 것이 좋은 머신 러닝 모델을 만드는 관건이다.
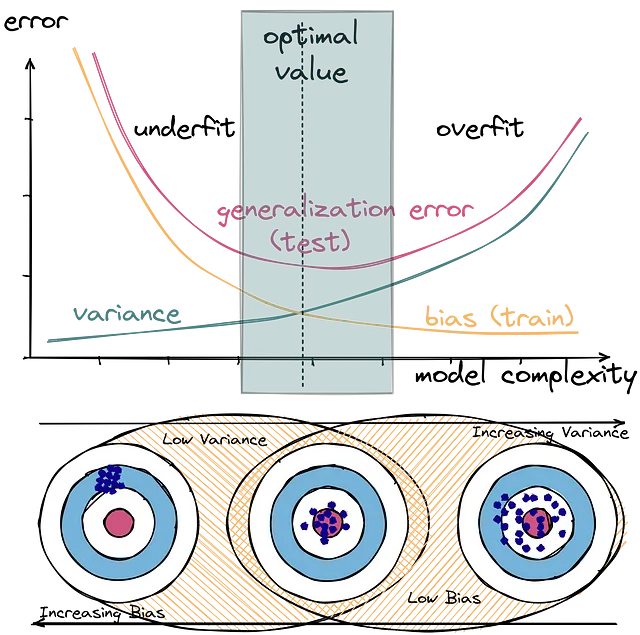 어떤 Medium 블로그에서는 위와 같은 이미지를 들어서 설명하기도 하더라. Bias & variance가 어떻게 underfitting/overfitting으로 이어지는 지를 직관적으로 표현한 그림이다. 일반적으로 bias와 variance는 모델의 표현력이나 민감성에 관련된 지표로 받아들일 수 있다.
어떤 Medium 블로그에서는 위와 같은 이미지를 들어서 설명하기도 하더라. Bias & variance가 어떻게 underfitting/overfitting으로 이어지는 지를 직관적으로 표현한 그림이다. 일반적으로 bias와 variance는 모델의 표현력이나 민감성에 관련된 지표로 받아들일 수 있다.
가령, 선형회귀 모델로 복잡한 곡선을 fit하려고 한다고 생각해보자. 이 경우 모델은 데이터의 분포에 선형으로 충분히 fit할 수 있을거라는 (지나치게 단순한) 가정을 하고 있다 (즉, bias가 도입되었다). 이 경우 모델이 데이터를 제대로 fit하지 못하는 underfitting 문제가 발생한다.
다른 예로, 어떤 (충분한 표현력을 가진; Low bias) 다항 회귀 모델이 모든 데이터에 대해 지나치게 fit해버렸다(overfitting). 이 경우 모델이 학습 데이터에 대해 너무 민감하게 반응했다(즉, 큰 variance를 가지게 되었다.) 라고 해석할 수 있다.
요약하면,
- 지나치게 단순한 모델은 학습 데이터에 대한 민감도는 떨어지지만(low variance), 낮은 표현력(high bias)을 가지게 되어 underfit하는 경향이 있다.
- 지나치게 복잡한 모델은 높은 표현력(low bias)을 가지지만 이로 인해 학습 데이터에 너무 민감하게 반응하여(high variance) overfit하는 경향이 있다.
위의 직관들을 유념하고 inductive bias에 대해 살펴보자.
Inductive Bias
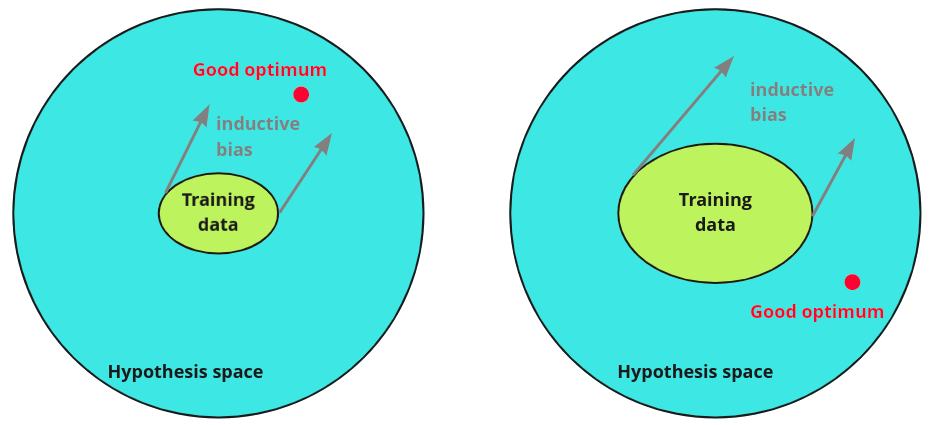 위 그림은 올바른 inductive bias를 도입한 경우(좌)와 그렇지 못한 경우(우)를 간단하게 보여준다.
위 그림은 올바른 inductive bias를 도입한 경우(좌)와 그렇지 못한 경우(우)를 간단하게 보여준다.
Inductive bias도 역시 이름에서 알 수 있듯 bias이고, 위에서 설명했듯이 bias는 모델의 표현력의 약간의 제한을 걸어주는 역할(regularization)을 수행해준다. 그런데, bias는 무조건 줄이는 것이 좋은 게 아니었나?
사실, 오히려 적당한 inductive bias는 학습에 도움을 준다. 구체적으로 말하면, 왼쪽 그림처럼 더 적은 양의 데이터로 목표 지점(Good optimum)에 빨리 도달할 수 있도록 만들어준다. 위에서 설명한 선형 회귀 예시에서, 만약 데이터가 직선으로도 충분히 fit할 수 있는 단순한 분포를 가지고 있었다면, 선형 회귀 모델을 사용하는 것은 오히려 좋은 inductive bias를 도입하는 셈이 되었을 것이다.
하지만, 다항 회귀 모델로 fit해야 하는 복잡한 데이터에 선형 회귀 모델을 가져다 댄다면, 그것은 잘못된 inductive bias를 도입한 것과 같다고 해석할 수 있다.
Inductive bias(유도 편향)는 이렇듯 모델을 특정 방향으로 유도해주는 가이드라인 역할을 해주는 bias로, 잘만 사용하면 적은 데이터로 빠르게 학습할 수 있게 도와준다.
Inductive Bias in Deep Learning
선형 회귀 모델이 “선형”이라는 inductive bias를 가지듯이, 우리에게 친숙한 딥러닝 모델들도 저마다의 inductive bias를 가지고 있는 경우가 있다.
CNN의 경우, convolution 연산을 통해 인접한 픽셀 정보를 학습하기 때문에, “locality”의 inductive bias를 가지고 있으며, RNN의 경우 순차적으로 데이터를 학습하기 때문에 “sequential”한 inductive bias를 가지고 있다. 이렇듯 inductive bias는 각각의 모델이 그 구조로 인하여 가지게 되는 표현력의 특징이며, 저마다의 모델이 가진 필살기와 같다. 애초에, 위 모델들은 그러한 데이터(CNN은 이미지, RNN은 시퀀스)를 학습하는 데에 특화되어 있도록 설계된 모델들이기도 하다.
반면, MLP나 Transformer의 경우 모든 input과 모든 output이 대응되는 all-to-all 연산이기 때문에, 이러한 inductive bias가 약하다고 볼 수 있다.
Inductive bias & variance trade-off
Inductive bias도 bias라면 당연히 bias & variance trade-off가 발생하기 마련이다. Vision-Transformer와 CNN을 비교해보자.
일반적으로 Vision-Transformer는 CNN이 가지고 있는 inductive bias가 부족해(low bias) 뛰어난 표현력을 가지지만 이로 인한 학습 데이터에 대한 민감도가 커서(high variance) 쉽게 overfit할 수 있다. 다시 말해, overfit하지 않기 위해 더 많은 양의 데이터가 필요하다(사실 요즘같이 엄청난 large-scale의 데이터에 학습시키는 시대에 variance는 이미 고려 대상에서 제외되었는지도 모르겠다).
반면 CNN은 inductive bias가 도입되어 비교적 적은 양의 데이터에 대해 금방 학습하지만, 단순한 표현력(high bias), 낮은 민감도(low variance)로 인해 다양한 데이터에 대한 강건함(robustness)가 부족한 편이다.
물론 CNN도, ViT도, 지속적으로 아키텍처 개선을 위한 연구가 이루어지고 있기 때문에 위 주장을 모든 경우에 대해 일반화할 수는 없지만, 분명히 inductive bias는 양날의 검인듯 하다. 현대 최신의 딥러닝 연구들은 막대한 양의 학습 데이터셋를 기반으로 inductive bias를 뛰어넘는 성능을 보여주고 있는 편이다.

Comments